I watched the NFC Championship game the weekend before last via a moderately sketchy British stream. It used the Joe Buck/Troy Aikman feed, but whenever that went to commercials they had their own British commentary team whose level of insight, I think it’s fair to say, was probably a notch below what you’d get if you picked three thoughtful-looking guys at random out of an American sports bar. (To be fair, that’s arguably true of most of the American NFL studio crews as well.)
When discussing Marshawn Lynch, one of them brought out the old chestnut that big running backs wear down the defense and thus are likely to get big chunks of yardage toward the end of games, citing Jerome Bettis as an example of this. This is accepted as conventional wisdom when discussing football strategy, but I’ve never actually seen proof of this one way or another, and I couldn’t find any analysis of this before typing up this post.
The hypothesis I want to examine is that bigger running backs are more successful late in games than smaller running backs. All of those terms are tricky to define, so here’s what I’m going with:
- Bigger running backs are determined by weight, BMI, or both. I’m using Pro Football Reference data for this, which has some limitations in that it’s not dynamic, but I haven’t heard of any source that has any dynamic information on player size.
- Late in games is the simplest thing to define: fourth quarter and overtime.
- More successful is going to be measured in terms of yards per carry. This is going to be compared to the YPC in the first three quarters to account for the baseline differences between big and small backs. The correlation between BMI and YPC is -0.29, which is highly significant (p = 0.0001). The low R squared (about 0.1) says that BMI explains about 10% of variation in YPC, which isn’t great but does say that there’s a meaningful connection. There’s a plot below of BMI vs. YPC with the trend line added; it seems like close to a monotonic effect to me, meaning that getting bigger is on average going to hurt YPC. (Assuming, of course, that the player is big enough to actually be an NFL back.)

My data set consisted of career-level data split into 4th quarter/OT and 1st-3rd quarters, which I subset to only include carries occurring while the game was within 14 points (a cut popular with writers like Bill Barnwell—see about halfway down this post, for example) to attempt to remove huge blowouts, which may affect data integrity. My timeframe was 1999 to the present, which is when PFR has play-by-play data in its database. I then subset the list of running backs to only those with at least 50 carries in the first three quarters and in the fourth quarter and overtime (166 in all). (I looked at different carry cutoffs, and they don’t change any of my conclusions.)
Before I dive into my conclusions, I want to preemptively bring up a big issue with this, which is that it’s only on aggregate level data. This involves pairing up data from different games or even different years, which raises two problems immediately. The first is that we’re not directly testing the hypothesis; I think it is closer in spirit to interpret as “if a big running back gets lots of carries early on, his/his team’s YPC will increase in the fourth quarter,” which can only be looked at with game level data. I’m not entirely sure what metrics to look at, as there are a lot of confounds, but it’s going in the bucket of ideas for research.
The second is that, beyond having to look at this potentially effect indirectly, we might actually have biases altering the perceived effect, as when a player runs ineffectively in the first part of the game, he will probably get fewer carries at the end—partially because he is probably running against a good defense, and partially because his team is likely to be behind and thus passing more. This means that it’s likely that more of the fourth quarter carries come when a runner is having a good day, possibly biasing our data.
Finally, it’s possible that the way that big running backs wear the defense down is that they soften it up so that other running backs do better in the fourth quarter. This is going to be impossible to detect with aggregate data, and if this effect is actually present it will bias against finding a result using aggregate data, as it will be a lurking variable inflating the fourth quarter totals for smaller running backs.
Now, I’m not sure that either of these issues will necessarily ruin any results I get with the aggregate data, but they are caveats to be mentioned. I am planning on redoing some of this analysis with play-by-play level data, but those data are rather messy and I’m a little scared of small sample sizes that come with looking at one quarter at a time, so I think presenting results using aggregated data still adds something to the conversation.
Enough equivocating, let’s get to some numbers. Below is a plot of fourth quarter YPC versus early game YPC; the line is the identity, meaning that points above the line are better in the fourth. The unweighted mean of the difference (Q4 YPC – Q1–3 YPC) is -0.14, with the median equal to -0.15, so by the regular measures a typical running back is less effective in the 4th quarter (on aggregate in moderately close games). (A paired t-test shows this difference is significant, with p < 0.01.)

A couple of individual observations jump out here, and if you’re curious, here’s who they are:
- The guy in the top right, who’s very consistent and very good? Jamaal Charles. His YPC increases by about 0.01 yards in the fourth quarter, the second smallest number in the data (Chester Taylor has a drop of about 0.001 yards).
- The outlier in the bottom right, meaning a major dropoff, is Darren Sproles, who has the highest early game YPC of any back in the sample.
- The outlier in the top center with a major increase is Jerious Norwood.
- The back on the left with the lowest early game YPC in our sample is Mike Cloud, whom I had never heard of. He’s the only guy below 3 YPC for the first three quarters.
A simple linear model gives us a best fit line of (Predicted Q4 YPC) = 1.78 + 0.54 * (Prior Quarters YPC), with an R squared of 0.12. That’s less predictive than I thought it would be, which suggests that there’s a lot of chance in these data and/or there is a lurking factor explaining the divergence. (It’s also possible this isn’t actually a linear effect.)
However, that lurking variable doesn’t appear to be running back size. Below is a plot showing running back BMI vs. (Q4 YPC – Q1–3 YPC); there doesn’t seem to be a real relationship. The plot below it shows difference and fourth quarter carries (the horizontal line is the average value of -0.13), which somewhat suggests that this is an effect that decreases with sample size increasing, though these data are non-normal, so it’s not an easy thing to immediately assess.

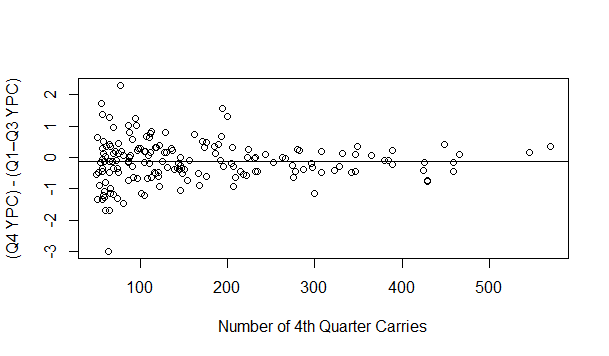
That intuition is borne out if we look at the correlation between the two, with an estimate of 0.02 that is not close to significant (p = 0.78). Using weight and height instead of BMI give us larger apparent effects, but they’re still not significant (r = 0.08 with p = 0.29 for weight, r = 0.10 with p = 0.21 for height). Throwing these variables in the regression to predict Q4 YPC based on previous YPC also doesn’t have any effect that’s close to significant, though I don’t think much of that because I don’t think much of that model to begin with.
Our talking head, though, mentioned Lynch and Bettis by name. Do we see anything for them? Unsurprisingly, we don’t—Bettis has a net improvement of 0.35 YPC, with Lynch actually falling off by 0.46 YPC, though both of these are within one standard deviation of the average effect, so they don’t really mean much.
On a more general scale, it doesn’t seem like a change in YPC in the fourth quarter can be attributed to running back size. My hunch is that this is accurate, and that “big running backs make it easier to run later in the game” is one of those things that people repeat because it sounds reasonable. However, given all of the data issues I outlined earlier, I can’t conclude that with any confidence, and all we can say for sure is that it doesn’t show up in an obvious manner (though at some point I’d love to pick at the play by play data). At the very least, though, I think that’s reason for skepticism next time some ex-jock on TV mentions this.