Short summary: I look at how much year-over-year persistence there is in the lists of best position players and pitchers, using Wins Above Replacement (WAR). It appears as though there is substantial volatility, with only the very best players being more likely than not to repeat on the lists. In the observed data, pitchers are slightly more likely to remain at the top of the league than position players, but the difference is not meaningful.
Last week, Sky Kalkman posted a question that I thought seemed interesting.
Sky’s Theorem: the group of aces has a half-life of two years. If you’re an ace, 50/50 you’re one in two years. Anyone want to research it?
— Sky Kalkman (@Sky_Kalkman) July 9, 2014
Obviously, this requires having a working definition of “ace,” for which Kalkman later suggests “the top dozen-ish” pitchers in baseball. That seems reasonable to me, but it raises another question: what metric to use for “top”?
I eventually wound up using an average of RA9-WAR and FIP-WAR (the latter being the standard WAR offered by FanGraphs). There are some drawbacks to using counting stats rather than a rate stat, specifically that a pitcher that misses two months due to injury might conceivably be an ace but won’t finish at the top of the leaderboard. That said, my personal opinion is that health is somewhat of a skill and dependability is part of being an ace.
I chose to use this blend of WAR (it’s similar to what Tangotiger sometimes says he uses) because I wanted to incorporate some aspects of Fielding Dependent Pitching into the calculations. It’s a bit arbitrary, but the analysis I’m about to present doesn’t change much if you use just FIP-WAR or plain old FIP- instead.
I also decided to use the period from 1978 to the present as my sample; 1978 was the expansion that brought the majors to 26 teams (close to the present 30), keeping the total pool of talent reasonably similarly-sized throughout the entire time period while still providing a reasonably large sample size.
So, after collecting the data, what did I actually compute? I worked with two groups—the top 12 and top 25 pitchers by WAR in a given year—and then looked at three things. I first examined the probability they would still be in their given group the next year, two years after, and so on up through 10 years following their initial ace season. (Two notes: I included players tied for 25th, and I didn’t require that the seasons be consecutive, so a pitcher who bounced in and out of the ace group will still be counted. For instance, John Smoltz counts as an ace in 1995 and 2005 in this system, but not for the years 2001–04. He’s still included in the “ace 10 years later” group.) As it turns out, the “half-life” that Kalkman postulates is less than a year: 41% of top 25 pitchers are in the top 25 the next year, with that figure dropping to 35% for top 12 pitchers who remain in the top 12.
I also looked at those probabilities by year, to see if there’s been any shift over time—basically, is the churn greater or less than it used to be? My last piece of analysis was to look at the probabilities by rank in the initial year to see how much more likely the very excellent pitchers are to stay at the top than the merely excellent pitchers. Finally, I ran all of these numbers for position players as well, to see what the differences are and provide some additional context for the numbers.
I played around and ultimately decided that some simple charts were the easiest way to convey what needed to be said. (Hopefully they’re of acceptable quality—I was having some issues with my plotting code.) We’ll start with the “half-life” graph, i.e. the “was this pitcher still an ace X years later?” chart.
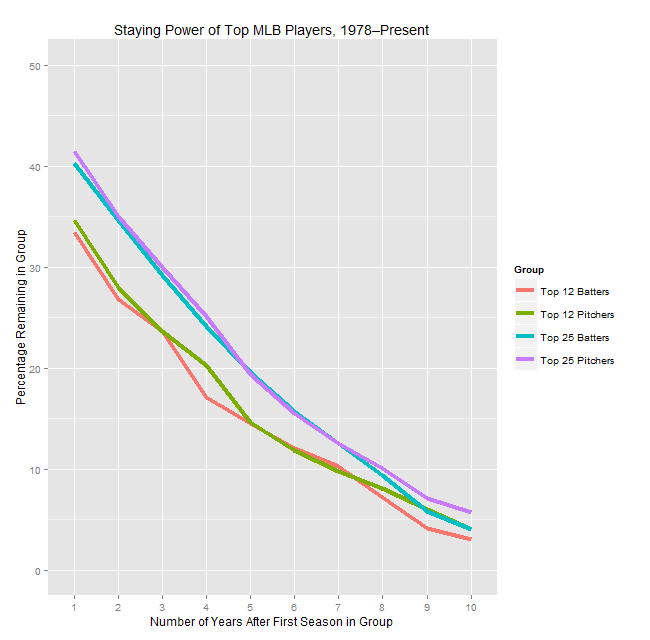
As you can see, there’s a reasonable amount of volatility, in that the typical pitcher who cracks one of these lists won’t be on the same list the next year. While there’s a small difference between pitchers and position players for each group in the one year numbers, it’s not statistically significant and the lines blur together when looking at years further out, so I don’t think it’s meaningful.
Now, what if we look at things by year? (Note that from here on out we’re only looking at the year-over-year retention rate, not rates from two or more years.)

This is a very chaotic chart, so I’ll explain what I found and then show a slightly less noisy version. The top 25 groups aren’t correlated with each other, and top 25 batters isn’t correlated with time. However, top 25 pitchers is lightly positively correlated with time (r = 0.33 and p = 0.052), meaning that the top of the pitching ranks has gotten a bit more stable over the last 35 years. Perhaps more interestingly, the percentage for top 12 pitchers is more strongly positively correlated with time (r = 0.46, p < 0.01), meaning that the very top has gotten noticeably more stable over time (even compared to the less exclusive top), whereas the same number for hitters is negative (r = -0.35, p = 0.041), meaning there’s more volatility at the top of the hitting WAR leaderboard than there used to be.
These effects should be more visible (though still noisy) in the next two charts that show just the top 12 numbers (one’s smoothed using LOESS, one not). I’m reluctant to speculate as to what could be causing these effects: it could be related to run environments, injury prevention, player mobility, or a whole host of other factors, so I’ll leave it alone for now. (The fact that any explanation might have to also consider why this effect is stronger for the top 12 than the top 25 is another wrinkle.)


The upshot of these graphs, though, is that (if you buy that the time trend is real) the ace half-life has actually increased over the last couple decades, and it’s gone down for superstar position players over the same period.
Finally, here’s the chart showing how likely a player who had a given rank is to stay in the elite group for another year. This one I’ve also smoothed to make it easier to interpret:

What I take away from these charts are that, unsurprisingly, the very best players tend to persist in the elite group for multiple years, but that the bottom of the top is a lot less likely to stay in the group. Also, the gaps at the far left of the graph (corresponding to the very best players) are larger than the gaps we’ve seen between pitchers and hitters anywhere else. This says that, in spite of pitchers’ reputation as being volatile, at the very top they have been noticeably less prone to large one-year drop offs than the hitters are. That said, the sample is so small (these buckets are a bit larger than 30 each) that I wouldn’t take that as predictive so much as indicative of an odd trend.
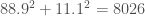 . David Price threw 66.7% fastballs, 5.8% sliders, 6.6% cutters, 10.6% curveballs, and 10.4% changeups, leading to an HHI of 4746. (See additional discussion below.) If you’re curious, the most and least concentrated repertoires split by role are in a table at the bottom of the post.
. David Price threw 66.7% fastballs, 5.8% sliders, 6.6% cutters, 10.6% curveballs, and 10.4% changeups, leading to an HHI of 4746. (See additional discussion below.) If you’re curious, the most and least concentrated repertoires split by role are in a table at the bottom of the post.