I was fortunate enough to be at SaberSeminar this past weekend, held at Boston University and organized by (among others) Dan Brooks, the titular Brooks of PitchF/X site BrooksBaseball. I took some notes throughout the weekend, and I’ve typed them up below, broken into smaller observations. (All of the reflection was done on the bus home, so any mistakes are my own due to typing with a fried brain.)
One other thing to tell is that I presented some research I did on shifts in the strike zone (it actually came out of this article about high socks), and I’m going to be writing that up as an article soon, though it may appear at a different site. All in all, quite an enjoyable weekend even after factoring in the scattered criticisms below.
It was my first time at a baseball conference and the first time I’d been at any conference in quite some time, and it actually struck me as pretty similar to an indie music festival. The crowd wasn’t huge (a couple hundred people), and they all knew most of the speakers, who mostly stuck to greatest hits sort of things. (Most of what I saw presented wasn’t novel, especially by the more prominent folk.) That’s not to take away from the sessions—it was still interesting to meet and hear people that I had only read, and it was still great to be around a group where everyone was interested in the same sort of stuff and you could bring up things like SIERA and wOBA without much risk of confusion.
They had a panel discussion featuring three of the Red Sox baseball operations interns, and I was reminded of how skeezy some aspects of that system are. The moderator talked about how there were fewer MLB intern slots than there used to be because the feds cracked down on illegal internships, which he framed as a bad thing. I found that a bit horrifying; it seems odd to me that a team with a payroll of hundreds of millions would cut staff rather than pay a semi-reasonable wage to their junior people. (Even if it makes economic sense, it seems like a bad way to treat people.)
The interns, for their part, didn’t offer a whole lot of insight into things. (Not that I blame them; it’s hard to be insightful during a panel discussion.) They twice dodged the question of how many hours they work, only saying “a lot.” (It’s possible I’m being too harsh and they actually don’t know; because I’m billed out by the hour at work, I have to keep very accurate time logs, which means I know how much I’ve worked every week since I’ve started, but I may be an outlier in that regard.) One of the failings of the panel was that it didn’t include anyone who had been an intern and washed out (either quit or wasn’t offered a job), which would have been more informative and more interesting. (I understand not wanting to irk any of the teams, but I don’t think this is too inflammatory.) This is the same problem I ran into in college a lot, where most of the advice I got about whether to get a Ph.D. came from people who had not only loved grad school but also met with astounding success afterward.
I also thought about the fact that they are hiring recent grads of extremely expensive schools (Columbia, Yale, and Georgetown, in this case) to be extremely underpaid interns; I wonder how much of their labor pool is indirectly disqualified simply due to a lack of connections or a need to make money for family or student loan reasons. It’s very puzzling to me that teams, despite being flush with cash, hire people similarly to high-prestige, low-money companies like magazines rather than high-prestige, rich firms like banks and tech companies. I’d love to see more discussion from people who know more about the industry than I do.
One mostly unstated theme that kept occurring to me throughout the weekend was the issue of class, opportunity, and privilege, which popped up in a number of different ways:
- Baseball Prospectus’s Russell Carleton discussed how teams can (or should) help their players develop into better adults by focusing on their financial, practical, nutritional, and mental well-being. While he focused mostly on the positive effects it would have on a player’s career and thus a team’s investment (fewer distractions and a better makeup will help talent win out), it seems to me that it’s a good thing in its own right to improve the life skills of the wash outs—especially the ones that skipped college and/or come from poorer backgrounds. Fewer guys in society who behave like Dirk Hayhurst’s teammates is probably a good thing.
- Tom Tippett, a senior analyst for the Red Sox, talked about how he always appreciates players that are diamonds in the rough, i.e. guys who went undrafted, played in the independent leagues, etc. The thing is, though, that equality of access doesn’t exist, and it’s an interesting thought experiment to think of how many guys get cut before they figure this out. In particular, I wonder how many guys are able to get to a good college or (building on Carleton’s point) hang around the minors longer (thus increasing the opportunity that they make the big leagues) because they have better “makeup” that really comes from growing up with a few more advantages.
- There was a demo of TrackMan, which is a portable radar system that can be used to evaluate pitch speed and rotation. One of the guys I was talking to pointed out that they’d sold as many of the systems as they could to clubs and agencies and were hoping to move on to selling it to amateurs. I don’t know what one costs, but the idea of buying a portable radar system for your high school pitcher seems like a caricature of what a rich family gunning for a scholarship would do (analogous to all of the academic tutoring and test prep that a lot of people I know did).
- Relatedly, a number of guys talked about the various high school showcases that pit the best high school talent in a region against each other, and one casually mentioned how much money they bring in. Again, seems like the sort of thing that serves to extract cash from hyperzealous parents and limit the opportunities for kids of less means, but I don’t know enough about the system to comment.
- Internship opportunities for big league teams, which I discussed above.
- I’ve been of the conviction for a while that pro sports would be equally or more enjoyable and substantially less ethically problematic if the teams were run as non-profits in the same general manner as art museums and whatnot (the Green Bay Packers are something like this already), and while I won’t go into that further here, if that were the case I think it’d be easier for a lot of the explicit privilege issues to be brought up in the game. While teams are still nominally concerned with profits, it’s a lot easier for them to sidestep problems that in a better world they could help address.
There were a number of talks with a more medical and scientific focus, and they provided good examples of how hard it is to apply these things rigorously to baseball (or any other real world application). There are lots of studies with very small N (“N=4” appeared on one slide describing research that had been published), and they are presumably subject to the same sorts of issues that all public health and social science papers are. While I’m sure lots of teams (in all sports) would love to bring in scientists to help them with things like sleep and vision, I imagine there’s a lot of stuff that falls apart between the lab and the field (if it even exists at all).
I should mention that the first talk of the conference, by a UC-Riverside professor who focuses on vision, did have experimental evidence of how improved vision helps college player performance, but it’s still tiny samples and only college students, and thus to be taken with a grain of salt.
There was an interesting panel featuring Matt Swartz, Ben Baumer, and Vince Gennaro discussing the relationship between winning and teams’ making money that prompted at least a couple article ideas for the future. Gennaro said he thought that the way teams spend money might change a bit after the addition of the second wild card, as there is now much greater variety across playoff teams in terms of how valuable the postseason slot is—the first seed became more valuable and the wild card slots substantially less. I have some thoughts on that, but will leave them for future articles.
Astros’ GM Jeff Luhnow gave a pleasant enough if relatively fact-free talk, the main focus of which was the importance of convincing the uniformed personnel of the importance of the sabermetric principles that buck conventional wisdom. He used the example of the shift and how it took the Astros three years to actually get people on board with it; obviously, if the players and the manager don’t like it, it won’t work as well as it would otherwise. I honestly wouldn’t be surprised if this becomes much less of an issue in 10 or so years, when the reasoning will have permeated a bit more through the baseball establishment and managers and young players will be a lot more open to things.
Vince Gennaro gave a very similar talk, and one thing he brought up was that you need to strike a balance between sticking to general principles (about shifting, pitcher workload, etc.) and making exceptions where warranted. Given that Luhnow talked about how he had made too many exceptions about when to shift last year, the point was hammered home, though it’s a vague enough point that it’s hard to really implement. (I was also reminded of this recent article about Ruben Amaro and exceptions.)
While Red Sox GM Ben Cherington didn’t discuss anything much more novel than what Luhnow covered, he was a lot more personable and down-to-earth while doing so. I imagine some of that is personality and a lot of it is the result of being the GM of the defending World Series champs and talking in his own backyard instead of presiding over three years of horrible teams and a lot of criticism from around baseball.
The last question asked of Luhnow was a minute-long ramble that wasn’t really a question and basically turned into “haha, you screwed up the Brady Aiken situation,” and Luhnow looked pretty peeved afterward, prompting Dan Brooks to tell the crowd not to be jerks to the presenters. There were a lot of bad questions all weekend, especially to Cherington, Red Sox manager John Farrell, and Luhnow, who clearly couldn’t say anything about their teams to us that was any more interesting than what they tell the media after a game. That didn’t stop people from bugging Farrell about his bullpen, though.
There was a bit more offensive humor in some of the talks than I would have expected—one professor made a joke about George W. Bush being brain damaged, and another managed to have a slide showing him wearing a t shirt that said “Drunk Bitches Love Me,” a slide with a cartoon captioned “I Will Fucking Cut You, Bitch,” and threw in a couple fat jokes for good measure. As anyone who knows me will attest, I have a reasonably sharp sense of humor, but throwing around jokes with misogynistic overtones at a conference that I would estimate was 90–95% men made me cringe.
More bullets from John Farrell’s talk:
- When asked (I believe by accomplished sabermetrician Mitchel Lichtman, aka MGL) about his handling of the bullpen on Friday night, he discussed how “it’s about 162 games” (specifically about pulling Koji Uehara after an easy inning). While that’s certainly important, I wonder how often it’s just used as a crutch to justify poor decisions. As Grantland’s Bill Barnwell has written before, you basically only ever see nebulous qualitative concerns like Uehara’s overwork invoked to defend conservative decisions, never more aggressive ones.
- Farrell thinks that the spree of Tommy John surgeries is more due to guys overthrowing (to impress scouts) than it is due to the sheer volume of pitches. The surgeon that spoke later in the conference disagreed.
- He mentioned that it’s easier to use less conventional strategies once opponents start doing it, because it seems more normal to the players. One obvious consequence of this is that really conspicuous tactical advances like shifting are going to be relatively short-lived advantages.
- He thinks that introducing replay and the corresponding promotion of several umpires has led to an expanded strike zone and that’s part of the continued downturn in baseball. That seems like a testable hypothesis, and something I’ll probably look at soon.
- Farrell mentioned that figuring out how guys will react when they fail as baseball players for the first time is an important part of helping players move through the system, which I guess is a big part of what Russell Carleton later talked about. It reminded me a lot of what people say about elite colleges and places like Stuyvesant High School, where a lot of people have to adjust from being in the 99th percentile of their peers at their prior institution to being median or below at their new one.
Russell Carleton gets major points for treating data as a plural noun rather than a singular one; he was the only one I noticed doing that all conference. I’d be curious to see what the usage rates are depending on background, with my guess being that people with more academic experience use “are” more than people who mostly use data in a private sector setting. (Yes, I’m a pedant about some of these things.)
Two White Sox notes from people’s presentations:
- Apparently Tyler Flowers is fifth in the bigs in saving runs by catch framing. Some of that is surely because of his workload, but it’s still a surprise.
- Not surprising, but something I’d forgotten: Erik Johnson was BP’s #1 prospect for the White Sox at the beginning of the year. Sigh.
Another one of those themes that kept popping up to me during the weekend was the idea of how teams preserve their edges, especially the ones they derive through quantitative and sabermetric means. (I’m reminded of the Red Queen hypothesis, which is an evolutionary biology idea I learned about through quiz bowl that applies pretty well to baseball analysis. Basically, you have to keep advancing in absolute terms to stay in the same place relatively, because if you are complacent people will catch up to you naturally.) A few places that this issue manifested itself:
- MGL said that, for general short term forecasting, any of the major projection public systems (Oliver, Steamer, PECOTA, and ZiPS) will do. He actually suggested that teams were probably wasting their time trying to come up with a better general forecasting system and that understanding volatility and more specific systems is probably more important. Jared Cross, developer of Steamer, disagreed a little bit; his view was that the small gap between current projection systems and perfect estimates meant that a seemingly marginal improvement would actually mean a lot because of how competitive things are.
- The sort of innovations Carleton discussed are the sort of thing that would pretty quickly spread throughout baseball, making any one team;s advantage relatively fleeting. Of course, if it spreads then it’s likely to increase the overall quality of the talent pool, which would lead to either better games or more teams, which is probably good. (It’s not necessarily good for the current players; any progress in player evaluation and development is unlikely to actually help players, given that the total number of jobs isn’t increasing; if one player does better, another loses his job.)
- Tom Tippett said that if he had his druthers the public wouldn’t have access to PitchF/X data, because it allows teams who don’t have good analysts to borrow heavily from the public and thus decreases the advantage that analytically-inclined organizations hold. While I think that’s true from his self-interested perspective, I think it’s a bit short-sighted overall, and I wish he’d answered with a “good for the game” perspective. When you think about what’s best for fans, I think defending closed systems is probably harder; one of the things I like about baseball is how freely available the data are, and to the extent that becomes less true I think it’s a sad thing.
- On that note, I’m a bit amused by what people think of as being “trade secrets”; there were lots of teams bouncing around and a few presentations by companies that are using highly proprietary data analysis methods that they are trying to sell people on. Again, it’s hard for me to evaluate how meaningful that stuff is (though people love kicking around the figure that pro teams are five years ahead of the public in their understanding of things), but even if it does represent a competitive advantage it’s still pretty funny to step back and think about the secrecy that’s applied to sports.
Several different people brought up StatCast, which is the new data collection system MLB Advanced Media is going to roll out some time soon; it will provide a huge amount of data on how fast players move and how quickly they react that will allow for analysis that’s a bit more along the lines of what the SportVU cameras do in basketball. (See the videos in the above link for examples.) There’s still no sense of whether or not it will be made public (and in what form it might be made public), but people were uniformly excited about it.
The projections folk were united in the belief that it would have a huge effect on projecting defense, to the point where MGL thinks defense will go from being the hardest component of the sport to analyze and predict to the easiest. There was a bit more divergence about what it might do for pitching and batting analysis, as well as about when it would come out—one speaker quoted MLB and said it would be ready to go by the beginning of next year, whereas Dave Cameron pointed out that test data hadn’t been released to the teams yet despite what was originally promised and thus thought it was highly unlikely that the data would be ready for teams by next year, much less ready for public consumption.
Dan Brooks jokingly introduced a hitting metric he called “GIP,” for Google Images Performance. It was prompted by the fact that a Google search for “miguel cabrera hitting” or “david ortiz hitting” finds pictures of them hitting home runs, whereas a query for “jose molina hitting” gets mostly pictures of him behind the plate.
More notes from Tippett’s talk:
- He started by mentioning that the hardest part of his job is deciding when a player’s underperformance is real and not just noise; I don’t think I’ve ever seen a rigorous evaluation of how to do that using Bayes’ rule and the costs of Type I and Type II errors (booting a good player and keeping a bad one, respectively), but I would love to read one. (How projection systems react to new performance data is in principle just Bayesian reasoning regardless.)
- He non-snarkily talked about the “momentum” that the Red Sox had, and nobody asked about it. All that probably means is that when he’s talking outside the office he’s perfectly willing to let a bit of narrative creep in.
- He talked about their decision to cut Grady Sizemore and how it was related to certain incentives in his contract that would have vested. I casually wonder how cavalier teams are allowed to be in explicitly making decisions based on players’ contract incentives, given that there have been talks about how players might opt to file grievances about these things in the past. (The one that comes to mind is Brett Myers, who would have had an option vest if he finished a certain number of games for the White Sox a couple years back. The commentary I read suggested that conspicuously changing his usage pattern would have been grounds for a grievance, but I don’t know how that applies to situations like Sizemore’s.)













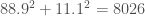 . David Price threw 66.7% fastballs, 5.8% sliders, 6.6% cutters, 10.6% curveballs, and 10.4% changeups, leading to an HHI of 4746. (See additional discussion below.) If you’re curious, the most and least concentrated repertoires split by role are in a table at the bottom of the post.
. David Price threw 66.7% fastballs, 5.8% sliders, 6.6% cutters, 10.6% curveballs, and 10.4% changeups, leading to an HHI of 4746. (See additional discussion below.) If you’re curious, the most and least concentrated repertoires split by role are in a table at the bottom of the post.

